Características adicionales de las versiones 2.x
Las versiones 2.x presentan importantes mejoras en las posibilidades de búsqueda en tres aspectos distintos: utilización de operadores booleanos, recuperación de la lista de formas o lemas únicos que presentan las características deseadas y distribución de las frecuencias según los diferentes parámetros utilizados en el corpus. Además, se ha incorporado un sistema de descarga de resultados adaptado a las nuevas funcionalidades.
1. Búsquedas con operadores booleanos
Los operadores booleanos permiten enriquecer o matizar una búsqueda. Por ejemplo, con el operador OR, representado por la pleca (|), es posible fundir en una consulta única dos o más consultas individuales. Así, incluir la expresión volver|regresar en el campo Lema nos devolverá todos los casos en los que se utilice una forma de cualquiera de estos verbos. Este operador puede ser utilizado también en las consultas por etiqueta. Si queremos recuperar los casos de uso del infinitivo o el gerundio del verbo volver escribimos volver en Lema, seleccionamos Verbo e Infinitivo en Etiqueta, añadimos la pleca (|) y luego seleccionamos la etiqueta correspondiente al gerundio. Al aceptar ese último valor, la ventana muestra que se borra el anterior, de modo que parece que no existe esta posibilidad de combinación. Sin embargo, si escribimos directamente en la ventana de Etiqueta VN*|VG* recuperaremos todos los casos de volver y volviendo.
De gran utilidad es el operador booleano NOT, que se representa mediante el signo de cierre de admiración (!). Si se quiere comprobar la frecuencia de uso del diminutivo en -iño, característico del gallego y del español de Galicia, puede escribirse *iño en la ventana de Texto de la opción Palab. ortográficas. La aplicación indica que hay 406 casos, con una frecuencia normalizada de 538 casos por millón. Sin embargo, un análisis superficial de las concordancias muestra que este resultado no responde exactamente a lo que buscamos porque, de acuerdo con lo que se pide, aparecen, entre otros, muchos casos de niño o cariño. Es fácil eliminarlos: en esa misma ventana se escribe *iño!niño!cariño y el número de casos se reduce a 81, con una frecuencia normalizada de 107 casos por millón.
Dado que el diminutivo tiene moción de género y número, la búsqueda anterior resulta parcial y debe ser mejorada. Si la ajustamos dando las cuatro posibilidades (*iño, *iña, *iños, *iñas) tendremos que excluir también niño, niña, niños, niñas, etc., lo cual resulta bastante pesado y no se beneficia de las ventajas de un corpus anotado y lematizado. La opción más lógica es utilizar la búsqueda por elementos gramaticales, escribir *iño|*iña|*iños|*iñas en la ventana de Elementos gramaticales y añadir en la ventana de Lema !niño!cariño. Con esta indicación, que combina dos operadores booleanos diferentes en dos aspectos distintos, la aplicación devuelve 237 casos. El análisis de las concordancias indica inmediatamente que sigue habiendo casos que convendría dejar a un lado porque son, por ejemplo, nombres de lugares (como Fontiñas o Cuspedriños). Es posible evitar estos casos usando el operador de negación en el campo correspondiente a la Etiqueta. Si se selecciona para ese campo el valor Sustantivo propio y se antepone el operador de negación, los casos se reducen a 102. Es fácil ver que quedan todavía formas que no nos interesan, como riña(s) o campiña(s), o fallos del etiquetador (aliño como sustantivo común), pero es sencillo, mediante estos operadores, eliminarlos y quedarnos únicamente con los que realmente son casos del diminutivo.
2. Resultados: inventarios de lemas y elementos gramaticales
La segunda novedad importante consiste en la posibilidad de obtener directamente la relación de formas ortográficas, elementos gramaticales o lemas distintos que tienen ciertas características, con indicación de la frecuencia de cada uno. En las versiones anteriores era posible obtener, por ejemplo, el número total de adjetivos terminados en -iño, -iña, -iños, -iñas, así como la frecuencia total y normalizada o la distribución en los diferentes parámetros presentes en el corpus de los elementos de este tipo. Sin embargo, llegar a la lista de elementos únicos con esta característica (es decir, la lista de adjetivos diferentes que se documentan con este diminutivo y la frecuencia de cada uno de ellos) requería reordenar primero las concordancias obtenidas y hacer luego el recuento de los elementos distintos de forma manual. No es un trabajo excesivo con elementos de este tipo (29 casos en total), pero la tarea resulta mucho más pesada si el objetivo es, por ejemplo, obtener la lista de verbos de la segunda conjugación presentes en el corpus con la frecuencia total de cada uno de ellos.
En la versión 2.2 hemos habilitado un procedimiento cómodo y muy potente que proporciona estos resultados de forma directa. Es la que aparece como Inventario en la ventana Tipo de resultado. Activando esta opción, eligiendo Adjetivo en la casilla de Etiqueta y escribiendo la secuencia con las terminaciones *iño|*iña|*iños|*iñas en la ventana de Elementos gramaticales se obtiene inmediatamente la lista de los 19 elementos de carácter adjetival documentados con este diminutivo y la frecuencia total y normalizada de cada uno de ellos. En los primeros puestos (que aparecen en orden de frecuencia decreciente) figuran pobriño, pobriña y pobriños. La forma en que se presentan los resultados se decide en la ventana Agrupar, que para esta opción tiene por defecto la organizada por elementos gramaticales. En el más que probable caso de que lo que nos interese sea la relación de lemas adjetivos que se documentan con este diminutivo, debemos ir a la ventana Agrupar, seleccionar Lema y anular Elemento gramatical. Ahora podemos ver que son únicamente 13 adjetivos distintos los que aparecen. En la ventana Agrupar cabe indicar también otros rasgos que pueden ser de interés para nuestra búsqueda, como hacer constar la etiqueta, la forma ortográfica, etc.
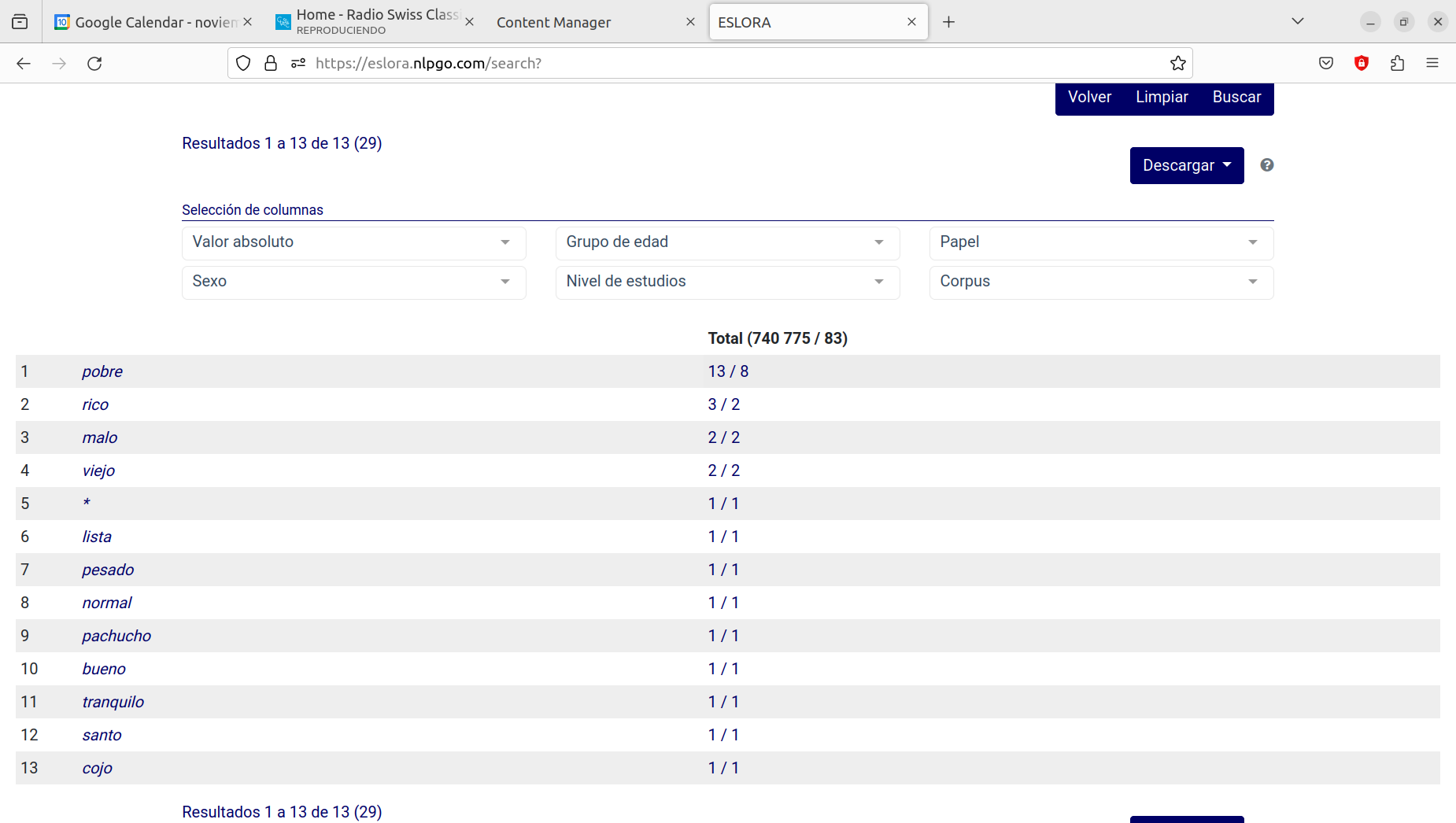
De modo semejante, escribiendo *er en la ventana de Lema, seleccionando Verbo en las etiquetas y activando la opción de Inventarios en los resultados se obtiene la lista de los 173 verbos de este tipo documentados en ESLORA. Con el mismo procedimiento se puede recuperar la lista de todos los sustantivos, todos los adverbios o, si se necesita, la lista de todos los lemas (o todos los elementos gramaticales o todas las formas ortográficas) contenidos en ESLORA.
Este tipo de resultados puede ser fácilmente asimilado a los diccionarios de frecuencias léxicas producidos tradicionalmente, pero los resultados son de mayor utilidad en, al menos, dos aspectos distintos. En primer lugar, la posibilidad de obtener datos referentes a elementos gramaticales, como hemos hecho ya con los verbos de la segunda conjugación. Del mismo modo, es posible obtener la relación de combinaciones de dos preposiciones consecutivas o de verbos seguidos inmediatamente por una preposición. Para búsquedas de este tipo es necesario incorporar también la opción de elementos sucesivos (con el signo + situado en la parte derecha de la pantalla). De esta forma podemos obtener la relación de verbos que van seguidos inmediatamente por una preposición. Como es lógico, para que el resultado sea realmente útil es necesario dejar únicamente los lemas en la ventana de Agrupar.
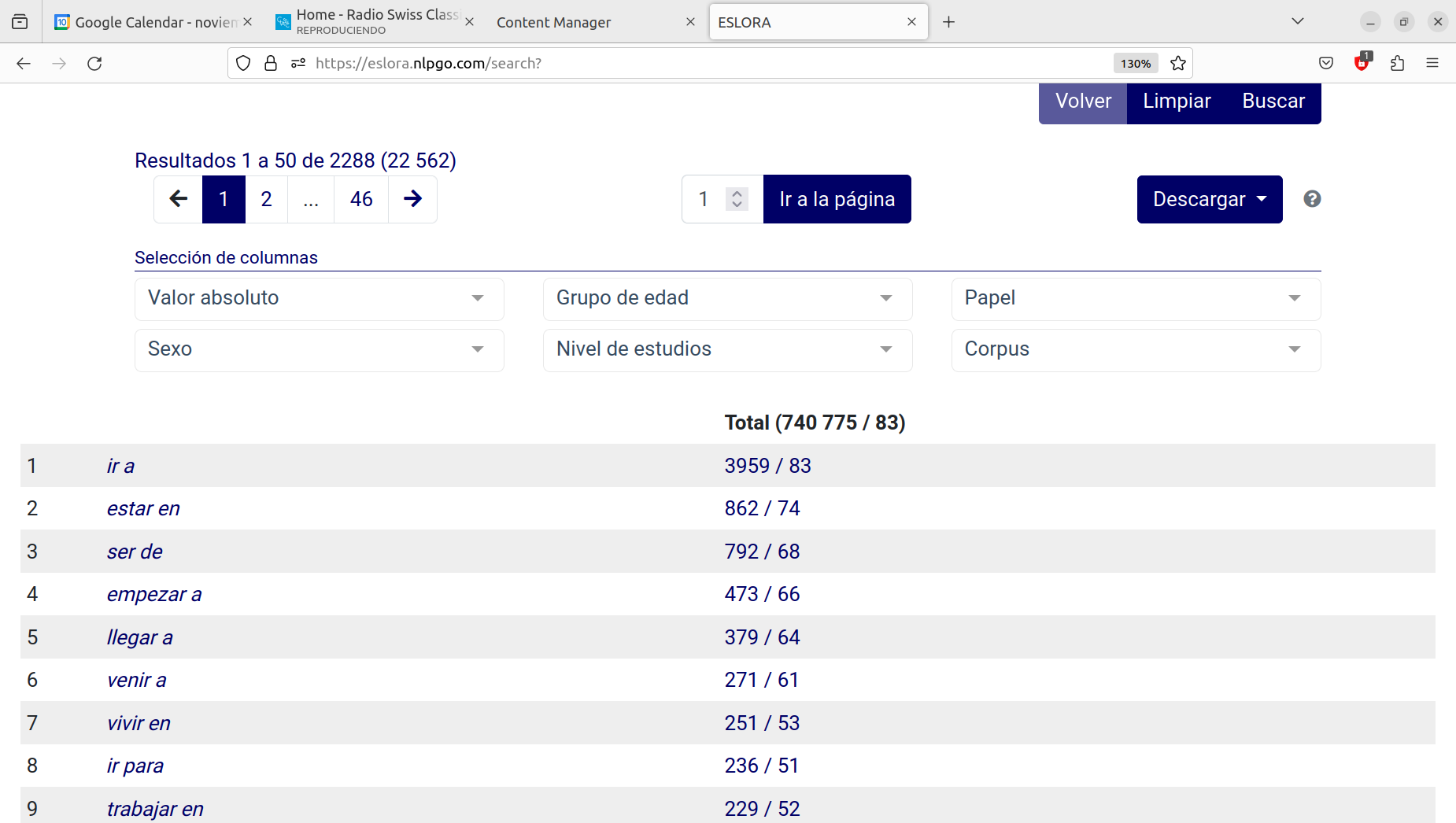
Dada la utilidad de estos cruces, se han incluido los más utilizados en la pestaña Listados, de modo que es posible obtener directamente la distribución de todos los elementos gramaticales y lemas del corpus según los diferentes parámetros utilizados en su configuración (edad, sexo, nivel de estudios, etc.).
Todos los datos obtenidos pueden ser descargados mediante la opción Descargas que aparece en la página de resultados. Puede hacerse con una página concreta o bien con todos los resultados y, en cualquiera de los dos casos, tanto en formato CSV, con campos separados por tabuladores, como en formato de Excel (Microsoft), utilizable también en Calc (de Libre Office) y en Numbers (de iWork).