Descripción del sistema de consulta
Introducción
La aplicación está organizada en diferentes módulos, a los cuales se accede pulsando la pestaña correspondiente en el menú superior.
En Información se ofrece la composición del corpus ESLORA en su última versión, tanto en general como en los subcorpus virtuales que se pueden construir mediante la selección de los diferentes valores que componen cada uno de los parámetros usados en su estructuración. Contiene también la relación de los códigos correspondientes a todos los hablantes del corpus junto con algunos datos identificativos. Además, contiene la composición del equipo de trabajo y la forma recomendada para citar ESLORA.
En Búsquedas se accede al núcleo de la aplicación de consulta, mediante la cual es posible recuperar datos de la totalidad de los textos incluidos o bien seleccionar el subcorpus de entrevistas o el de conversaciones. En cualquier caso, la búsqueda se puede organizar por:
- Palabras ortográficas (decir, del, diciéndome).
- Elementos gramaticales (dijo, de —incluyendo los casos de la contracción del—, diciendo —incluyendo los casos del tipo diciéndome, diciéndolo—, etc.).1
- Lemas (todas las formas del verbo decir).
- Clases de palabras (verbo, por ejemplo).
- Valores de las subcategorías gramaticales aplicables en cada caso (género y número en el caso de los sustantivos, etc.).
Todas estas posibilidades son, como veremos, combinables entre sí. Por otro lado, el sistema permite la recuperación de datos de la totalidad del corpus o bien del subcorpus virtual creado directamente por quien hace la consulta en función de las características de los hablantes utilizadas en la configuración de ESLORA:
- Edad
- Papel comunicativo
- Nivel de estudios
- Sexo
También en este caso es posible combinar distintos valores para cada uno de los parámetros señalados.
Por último, la ventana Buscar en permite referir las búsquedas a la totalidad del texto, que es la opción habitual, o bien centrarlas en fragmentos que han recibido cierta etiquetación (risa o con marca de énfasis, por ejemplo). Véanse las marcas de oral manejadas en relación de marcas de oral.
En los diferentes tipos de búsquedas, la aplicación permite trabajar con distintas opciones de Sensibilidad, como la consistente en tomar en cuenta la existencia de caracteres con tildes o diferenciar entre mayúsculas y minúsculas.
Los resultados de las búsquedas pueden consistir en proporcionar la frecuencia simple (general y normalizada), la frecuencia completa, la lista de concordancias y también la lista de elementos gramaticales o lemas coincidentes, es decir, aquellos que responden a los rasgos incluidos en la consulta.
La pestaña Dicc. de frecuencias da acceso a un módulo nuevo de la aplicación de consulta, que se describe con detalle en las novedades de la versión 2.0.
La pestaña de Descargas contiene el enlace a la versión textual del corpus y el formulario que deben cubrir las personas que deseen obtenerlo en su versión etiquetada.
Las pestañas Guía y Contacto contienen la información correspondiente a la denominación utilizada.
Búsquedas generales
Búsquedas: Es el núcleo del recurso y el lugar desde el que se puede recuperar la información contenida en el corpus. Los párrafos y secciones siguientes de este documento describen el contenido y posibilidades del sistema de consulta de la aplicación.
En la pestaña Búsquedas se accede a una pantalla en la que aparecen las opciones de selección disponibles.
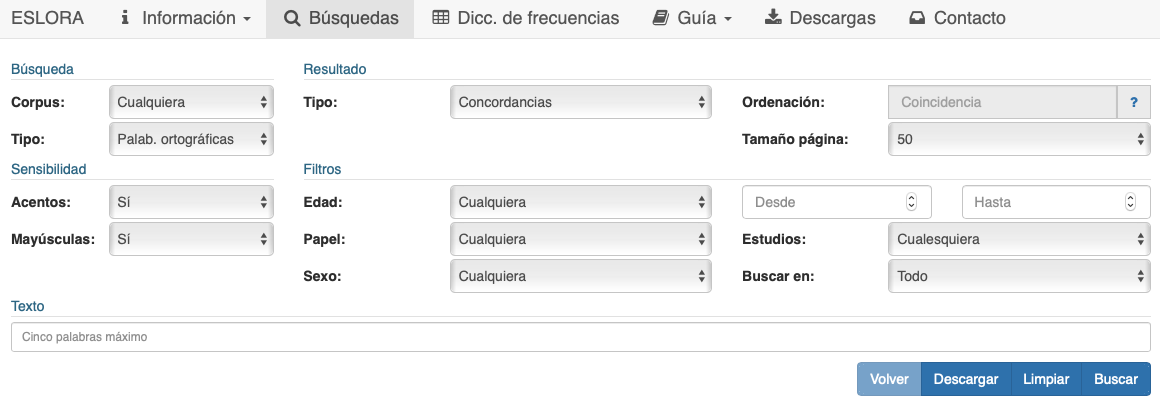
Como se observa en la fig. 1, en el bloque de Búsqueda se puede elegir el corpus de trabajo y el tipo de elementos que se desea localizar. La primera posibilidad consiste en hacer una búsqueda de palabras ortográficas, que, como indica la sección Texto en la que se introducen las secuencias, permite incluir hasta cinco palabras gráficas. Si escribimos llegaron en Texto, seleccionamos Frecuencia simple en Tipo de resultado y dejamos en todas las demás opciones los valores que la aplicación muestra por defecto, al pulsar el botón Buscar obtenemos la información de que esta forma ortográfica aparece en 26 casos localizados en 18 documentos distintos, lo cual equivale a una frecuencia normalizada de 34 casos por millón de palabras2.
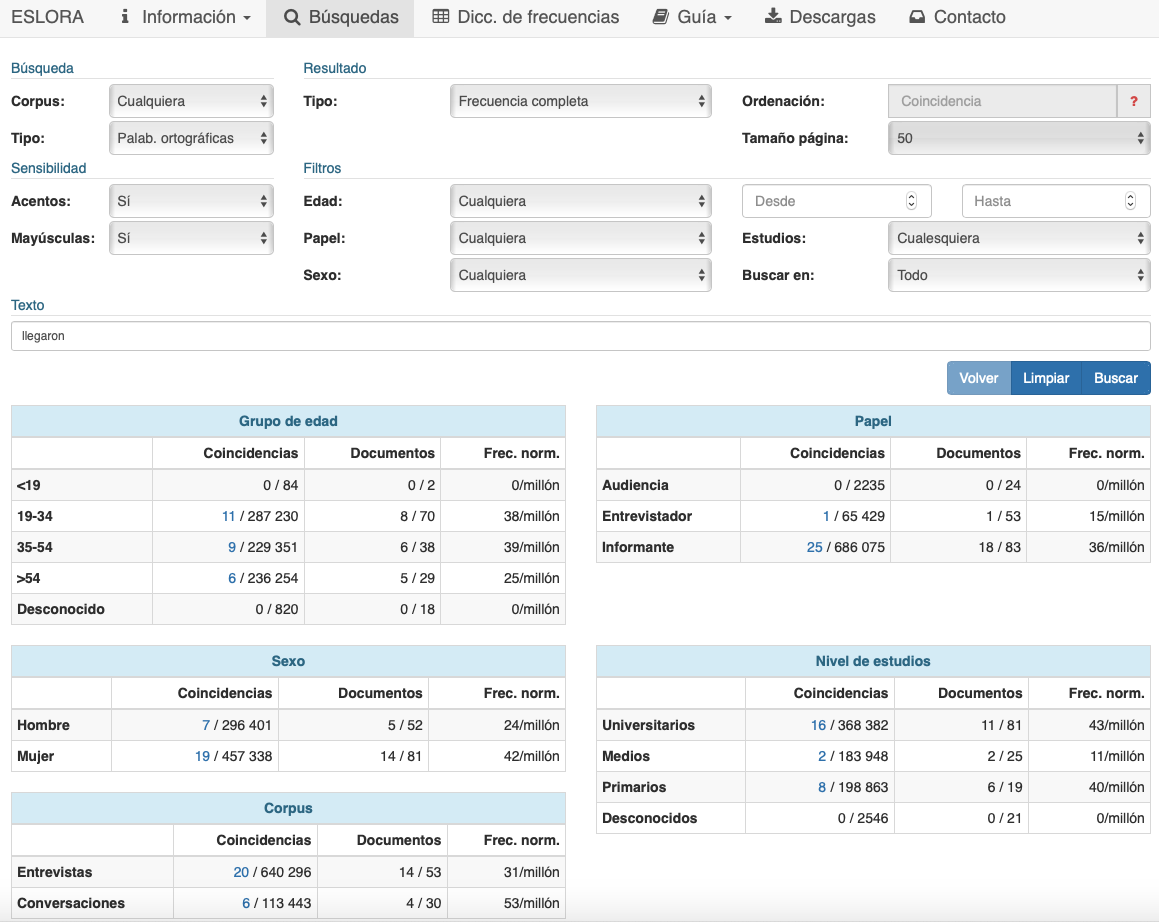
Si activamos ahora la opción Frecuencia completa en el campo Tipo (de resultados) obtenemos estos mismos datos, pero distribuidos ahora por los parámetros principales de estructuración del corpus, esto es, edad, papel, sexo y nivel de estudios, con lo que tendremos una panorámica general de la distribución de esta forma con respecto a todos los parámetros presentes en la configuración del corpus (vid. fig. 2).
El paso siguiente en la investigación puede consistir en el análisis individual de cada uno de los casos en los que aparece esta forma. Eso se consigue activando ahora la opción Concordancias en el campo Tipo de la sección Resultado (o bien pulsando la cifra que señala la cantidad de casos localizados en cada bloque de encuestas). Obtendremos entonces una pantalla como la que aparece en la figura 3:
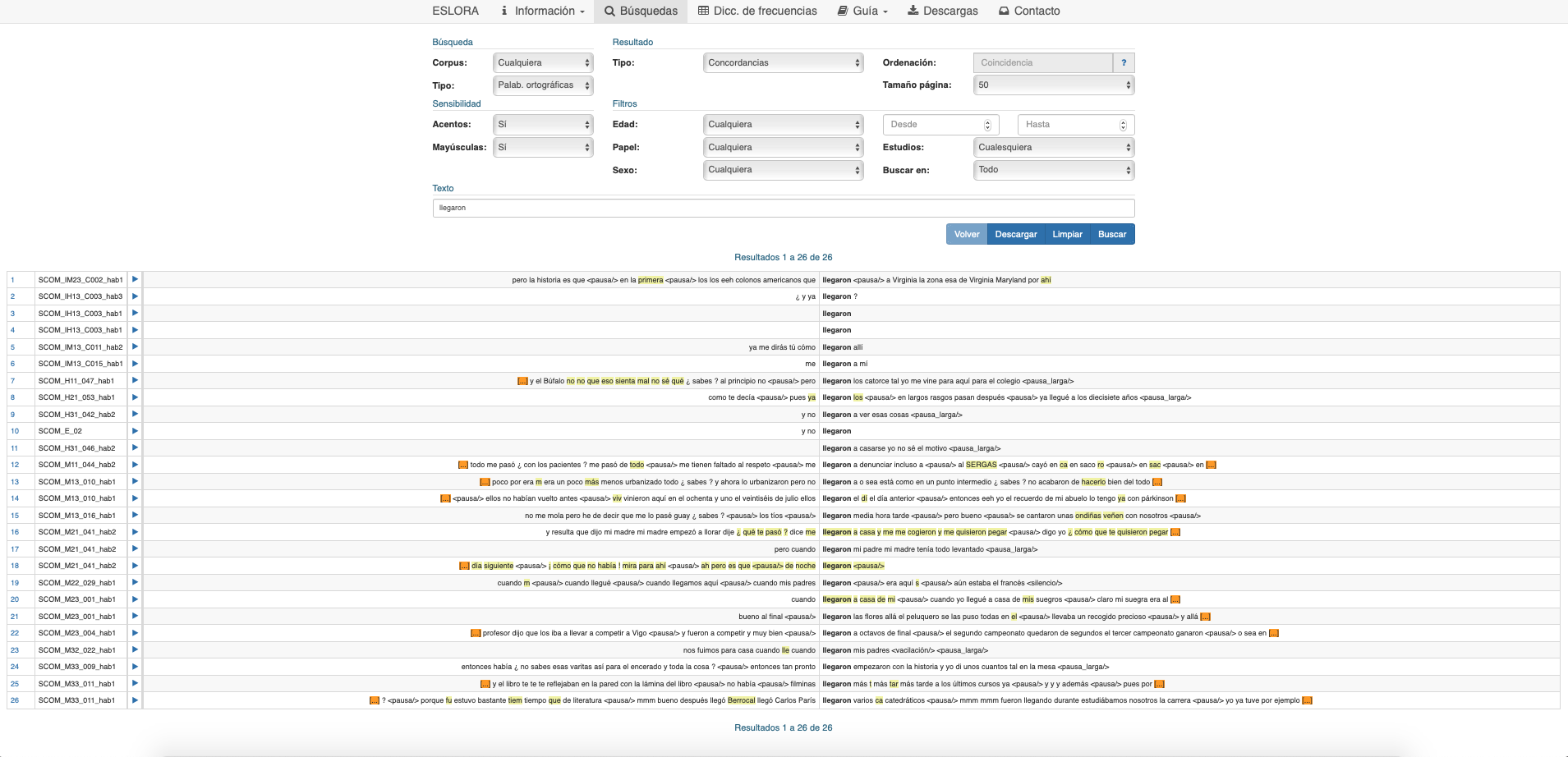
Como se ve, cada una de las concordancias aparece en una línea cuyo centro está ocupado por la forma que constituye el objeto de la búsqueda, acompañado de su contexto inmediato tanto anterior como posterior. La información que contiene esta pantalla es la siguiente (de izquierda a derecha):
- Número de orden de la concordancia. Al pulsarlo, se obtiene una ampliación del contexto correspondiente al ejemplo en cuestión (vid. infra).
- Referencia del texto al que corresponde la concordancia y del hablante que la ha pronunciado. Pasando el puntero del ratón sobre esta zona aparece un cuadro de texto con las características del hablante al que corresponde el texto seleccionado (papel, sexo, nivel de estudios y edad).
- Flecha que activa directamente la reproducción del sonido con el que está alineado el texto de la concordancia.
- Contexto inmediato en el que figura la secuencia buscada. Aparece en el formato KWIC (Key Word in Context) habitual e incluye algunas marcas consideradas de especial interés para la correcta interpretación del texto (pausas, por ejemplo). Para hacer más cómoda la lectura, las demás marcas no aparecen en el texto transcrito, pero se señala su existencia mediante el resalte del texto correspondiente en color amarillo. Al poner el puntero del ratón sobre las zonas destacadas aparece un cuadro de texto que indica la marca correspondiente (alargamiento, risas, etc.). Cf. relación de marcas de oral utilizadas en esta versión.
Los datos del texto y el hablante y la posibilidad de obtener el sonido aparecen también en la opción de contexto ampliado, ahora para cada una de las intervenciones que lo constituyen, pulsando la flecha que aparece en cada una de las líneas.
Entre las opciones que ofrece la pantalla de devolución de muestras, figura la de Descargar, que permite exportar el resultado obtenido al dispositivo desde el que se hace la consulta y, de esta forma, examinar los datos con más detención, filtrarlos, reordenarlos en función de características no incluidas en la aplicación, etc. El formato de devolución es TSV (Tab-separated values), es decir un texto plano que contiene el listado tabular con los diferentes campos de cada línea separados por tabuladores, lo cual automatiza su integración en cualquier hoja de cálculo o base de datos. El número de resultados que se puede obtener se decide en la opción de Tamaño de página. La producción de esos listados es sensible a la página de resultados en la que se encuentra la aplicación en el momento en que se solicita la descarga, de modo que si se hace desde el comienzo de la lista y se piden 50 proporcionará las concordancias 1 a 50, mientras que si se hace desde la concordancia número 101, la descarga contendrá desde esa línea hasta la 150. La opción "TSV completo" devuelve el texto con indicación de las marcas (cita, énfasis, etc.) que afectan a cada elemento.
Todas las posibilidades expuestas pueden ser refinadas mediante la indicación de valores específicos en cada uno de los parámetros reflejados en las distintas secciones del formulario de búsqueda:
- Corpus: Cualquiera / Entrevistas / Conversaciones.
- Tipo: Palabras ortográficas / Elementos gramaticales / Palabras ortográficas próximas / Elementos gramaticales próximos. Vid. infra.
- Sensibilidad: Permite que la recuperación se haga teniendo en cuenta la diferencia entre mayúsculas y minúsculas y entre vocales con tilde o sin ella.
- Filtros: Permite fijar valores específicos para los parámetros edad, sexo, nivel de estudios y papel desempeñado en la conversación o entrevista.
Véase también, más adelante, la posibilidad de seleccionar los casos en diferentes fragmentos del texto con la opción Buscar en.
Por otro lado, la sección Texto, cuando se buscan palabras ortográficas, permite la indicación de varias formas (hasta un máximo de cinco): en cuestión, por lo tanto, de ninguna manera, de vez en cuando, etc. son expresiones que se pueden recuperar directamente. Recurriendo a esta posibilidad, veamos ahora un ejemplo de búsqueda que utiliza, de forma progresivamente detallada, algunas de las características existentes en ESLORA. Si introducimos la secuencia de vez en cuando y activamos la opción Frecuencia completa de la sección Resultado, veremos que esta locución aparece con frecuencias generales bastante diferentes en los distintos grupos de edad, de modo que la frecuencia normalizada es de 28, 140 y 63 casos por millón de formas en los tres grupos de edad ordenados de forma ascendente. Al tiempo, se puede ver que las frecuencias normalizadas según sexo son de 98 y 59 casos por millón en hombres y mujeres, respectivamente. Podría considerarse que esas diferencias son suficientemente marcadas como para sugerir la conveniencia de analizar los ejemplos procedentes de cada uno de los subgrupos. La forma de hacerlo es sencilla: en la misma pantalla, sin necesidad de borrar los resultados anteriores, se activa la opción Concordancias (en el campo Tipo de la sección Resultado), Entre 35 y 54 (en Edad) y Mujer (en Sexo), se pulsa Buscar y aparecen en pantalla las 14 secuencias que reúnen todas estas características. Del mismo modo, activando las opciones pertinentes se pueden obtener los ejemplos que resultan de los cruces de cualesquiera de los diferentes parámetros tenidos en cuenta en la construcción del corpus.
Búsquedas más refinadas
La búsqueda mediante la opción de texto permite la utilización de algunos metacaracteres que facilitan ciertos tipos de recuperación. Así, por ejemplo, el signo de cierre de interrogación (?) sustituye a un carácter cualquiera que ocupe esa misma posición, de modo que la búsqueda de la secuencia c?sa devolverá los casos que contengan las secuencias casa, cosa, cesa. El asterisco () sustituye a secuencias de cero o más casos de cualquier carácter en la posición que ocupa. Así, por ejemplo, sal* recuperará todas las formas del verbo salir (incluyendo sal), pero también sala, salmuera, salchichón, etc. La expresión *mente devuelve todos los casos de adverbios terminados en -mente (pero también mente y, en general, todas las palabras terminadas con esa secuencia sean o no adverbios); salmos* muestra los casos que contienen salimos, salíamos, saldremos, saltamos, etc. Por último, la expresión ísim? (cualquier secuencia de caracteres seguida de la secuencia *ísim con algún otro carácter a continuación y seguido o no de alguna otra letra) devuelve todos los casos de las cuatro formas diferentes del superlativo sintético (-ísimo, -ísima, -ísimos e -ísimas). Como veremos a continuación, esta línea puede ser todavía mucho más útil e interesante si la combinamos con la indicación de valores referidos a aspectos gramaticales.
La posibilidad de emplear metacaracteres, mencionada en el párrafo anterior, supone un progreso considerable con respecto a las búsquedas individuales. Sin embargo, no es el camino más adecuado para dar respuesta a las necesidades de la investigación gramatical. Con uno de los ejemplos citados, es posible recuperar las formas del verbo salir recurriendo a la expresión sal* , que devolverá sal, sale, salimos, salgan, saldremos, etc. y también salado, salchichón, saldo, etc., de modo que tendremos todos los casos que nos interesan, aunque será necesario separarlos de aquellos que responden formalmente a lo que se ha pedido, pero no a lo que en realidad se está buscando. La línea adecuada es, por tanto, la de añadir a las formas que integran el corpus la información gramatical que les corresponde, indicando el lema al que pertenecen y también los valores que presentan en las categorías y subcategorías gramaticales que son de aplicación en cada caso. Es decir, el corpus debe contener la información de que saldremos es la primera persona del plural del futuro imperfecto de indicativo del verbo salir y que diciéndomelo es una forma ortográfica constituida por tres unidades gramaticales (el gerundio de decir, un pronombre átono de primera de singular y un pronombre átono de tercera de singular), etc.
Los textos que forman ESLORA han sido sometidos a una anotación morfosintáctica automática, lo cual permite lanzar búsquedas de carácter gramatical, abstracto, sobre los textos incluidos en el corpus. La activación de la opción Elementos gramaticales en el campo Tipo de la sección Búsqueda abre una nueva sección que contiene los campos de búsqueda Elemento gramatical, Etiqueta, Lema y Palabra ortográfica. Con ello, las posibilidades de búsqueda se enriquecen considerablemente y, sobre todo, permiten una formulación mucho más basada en conceptos gramaticales o léxicos que los que simplemente dependen de la forma gráfica.
El lema es el concepto que agrupa a todas las formas que pertenecen a, por ejemplo, el paradigma de un verbo o de un sustantivo. Por tanto, la indicación salir en el campo lema nos permitirá recuperar todos los casos que ESLORA contiene de ese verbo, a pesar de su irregularidad (sal, sale, salgo, saldré, salga, salimos, etc.). Es la forma más cómoda de recuperar de una vez todas las formas que corresponden al paradigma de un determinado sustantivo, adjetivo o verbo. Al tiempo, es el modo adecuado para discriminar entre las diferentes formas en los casos de homografía. Así, por ejemplo, recuerdo puede ser una forma del presente de indicativo del verbo recordar o bien la correspondiente al masculino singular del sustantivo recuerdo. Uno de los modos en los que se puede diferenciar entre ellas es activar la opción de Elementos gramaticales en el tipo de búsqueda, escribir recuerdo en forma ortográfica y recordar o recuerdo en el lema.
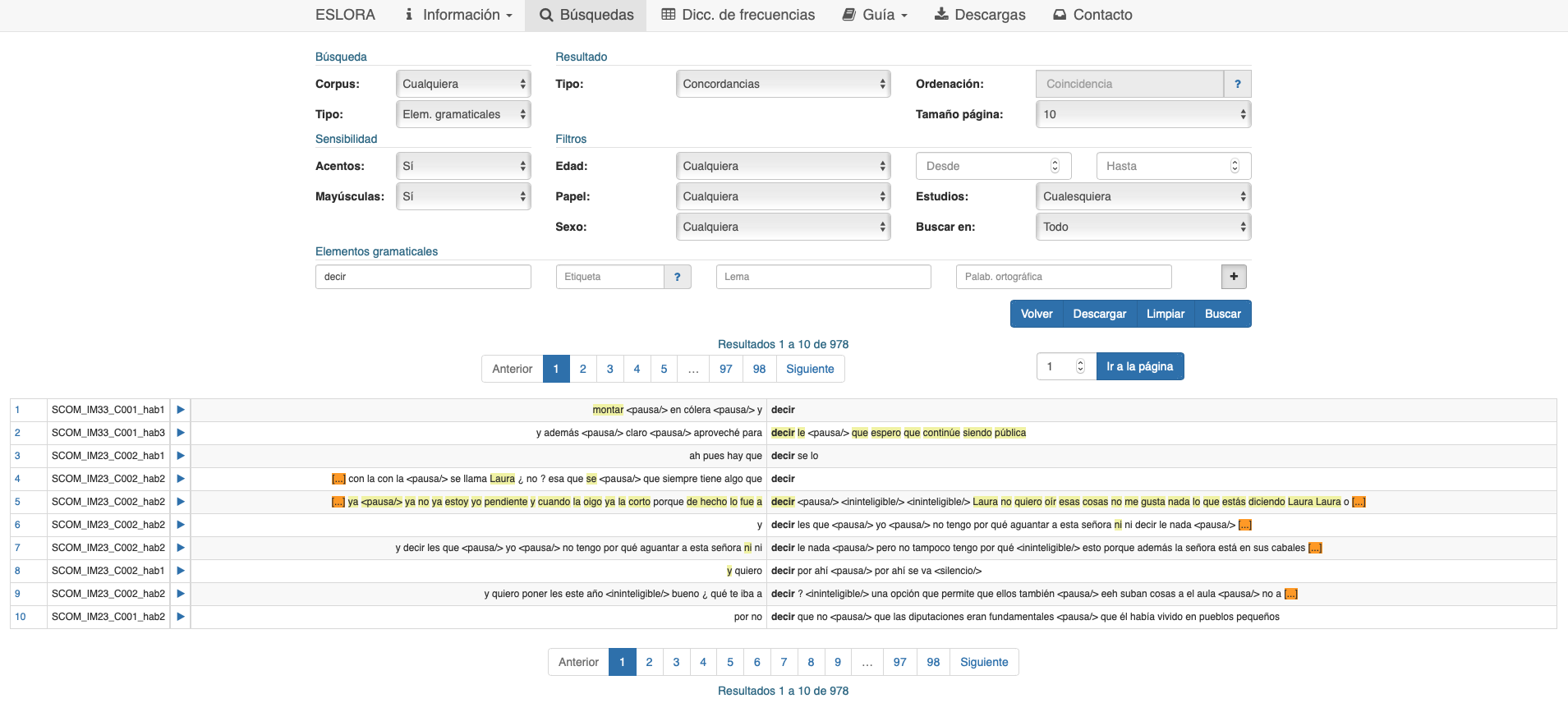
El empleo de la búsqueda de elementos gramaticales activa la posibilidad de acceder a las características gramaticales a mayor profundidad. La opción Concordancias presenta una pantalla del mismo tipo que las que hemos visto al hacer búsquedas por Palabras ortográficas, pero si se pulsa el número del ejemplo para acceder a un contexto más amplio se puede ver una pantalla en la que aparecen, además de las anteriores y posteriores a la central, cuatro líneas resaltadas que contienen diversas informaciones correspondientes a aquella que contiene el elemento recuperado, como muestra la pantalla de la fig. 4.

La primera es la línea de los elementos gramaticales existentes en el enunciado en cuestión, acompañados de las etiquetas directamente visibles. Nótese que, por ejemplo, los dos elementos haber y me de la forma ortográfica haberme aparecen separados. En la segunda línea están las etiquetas que reflejan la información acerca de los valores de las categorías y subcategorías gramaticales (vid. el etiquetario utilizado). La tercera contiene los lemas a los que corresponde cada uno de los elementos gramaticales existentes. Finalmente, en la cuarta aparecen las formas en su grafía convencional, lo cual obliga a repetir la forma haberme como correspondencia ortográfica de los dos elementos gramaticales señalados anteriormente.
Las búsquedas que usan la opción Elemento gramatical permiten recuperar los casos de una cierta palabra gramatical con independencia de su integración gráfica con otra u otras y también de la forma gráfica concreta que pueda presentar (vid. fig. 5). Así, la opción de búsqueda textual nos proporciona, en procesos distintos, los casos de decir, decirte y decírselo, todas las cuales (y muchas más) contienen el elemento gramatical decir. La indicación de decir en el campo Elemento gramatical permite recuperar todos los casos que lo contengan, es decir, los del tipo decir, decirte, decírtelo, etc. Nótese que, en el último caso, la forma gráfica es diferente, lo cual muestra con claridad que estamos trabajando con un elemento más abstracto que la simple apariencia ortográfica. La observación de las pantallas de resultados mostrará, por otra parte, que el texto de las concordancias no sigue las normas ortográficas, sino que separa en decir, se y lo los elementos gramaticales que existen en la forma gráfica decírselo.
La opción más rica es, por supuesto, la utilización de la etiqueta morfosintáctica. Como se ha visto en las pantallas precedentes, la información gramatical está resumida en una etiqueta que contiene todos los rasgos pertinentes. Sin embargo, para comodidad de manejo, la aplicación está organizada de modo que la etiqueta se puede ir construyendo a medida que se van introduciendo los rasgos deseados, sin necesidad de que los usuarios memoricen la organización de las etiquetas. La selección comienza por la clase de palabras y va dando luego las opciones existentes a medida que se van seleccionando rasgos. Para acceder a esta manera amigable de introducir las etiquetas es necesario pinchar en el signo de interrogación situado justo al lado del campo Etiqueta. De este modo es posible resolver los numerosos casos de homografías existentes. Con el ejemplo anterior, es posible obtener los casos en los que la forma ortográfica recuerdo ha sido adscrita a la clase de palabras verbo (que tiene una frecuencia normalizada de 324 casos por millón) y aquellos en los que se le atribuye la clase sustantivo (60 casos por millón):
El rasgo más potente de esta parte de la aplicación lo constituye la posibilidad de obtener los casos en los que, sin tener en cuenta el lema al cual pertenecen, las formas muestran unos determinados rasgos gramaticales. Mediante la organización jerarquizada de la construcción de etiquetas podemos, por ejemplo, saber cuántos casos de futuro de indicativo hay en los textos y analizarlos, uno a uno, en la opción Concordancias. Un paso más allá, es posible saber, por ejemplo, cuántos casos de la tercera persona del plural del futuro de indicativo (105 casos en la versión 2.0 del corpus) o de sustantivos en forma femenina plural están contenidos en los textos.
Es posible también referir la búsqueda a los textos completos, que es lo habitual, o bien a fragmentos de textos comprendidos entre ciertas marcas o situados en su contexto inmediato (por ejemplo, buscar texto que se haya producido entre risas o formas que contengan un alargamiento). Para conseguirlo hay que usar el campo Buscar en. Por ejemplo, para recuperar los casos de verbos en infinitivos situados en un fragmento que lleva la marca de énfasis, hay que hacer la indicación correspondiente en la ventana Etiqueta y luego, en Buscar en, activar la opción Énfasis.
La aplicación de consulta devuelve, por defecto, páginas de 50 resultados y las organiza según el texto en el cual aparecen. En el campo Ordenación es posible cambiar ambas posibilidades y obtener, por ejemplo, páginas que contengan 100 enunciados o que los muestren organizados según la edad de los emisores.
Búsquedas combinadas
Además de las búsquedas de elementos individuales, la aplicación admite la búsqueda de combinaciones de elementos. La más sencilla es la ya vista combinación de varias palabras gráficas (del estilo de de vez en cuando y similares).
La potencia de la recuperación de combinaciones y su utilidad para el trabajo gramatical se ofrece en toda su extensión cuando se le añade la posibilidad de utilizar directamente rasgos gramaticales, independientes de las formas que los soportan (vid. fig. 6). En primer lugar, es posible construir búsquedas constituidas por hasta cinco elementos seguidos. El modo de hacerlo consiste en seleccionar la opción Elem. gramaticales en el campo Tipo de la sección Búsqueda e ir pulsando el botón con el signo + que aparece a la derecha de la destinada a recoger la palabra ortográfica. Así, por ejemplo, para ver los casos en los que aparece la construcción ir a + infinitivo, se escribe el lema ir en el primer campo, se pulsa el signo + y se incluye el lema a en el segundo, de nuevo el signo + y la etiqueta correspondiente a verbo en infinitivo en el tercero, con lo que se obtiene la información de que esta perífrasis presenta una frecuencia normalizada de 3206 casos por millón. Por supuesto, detallando más la etiqueta se pueden obtener también, por ejemplo, los casos en los que la forma del verbo auxiliar está en tercera persona del singular del presente de indicativo.
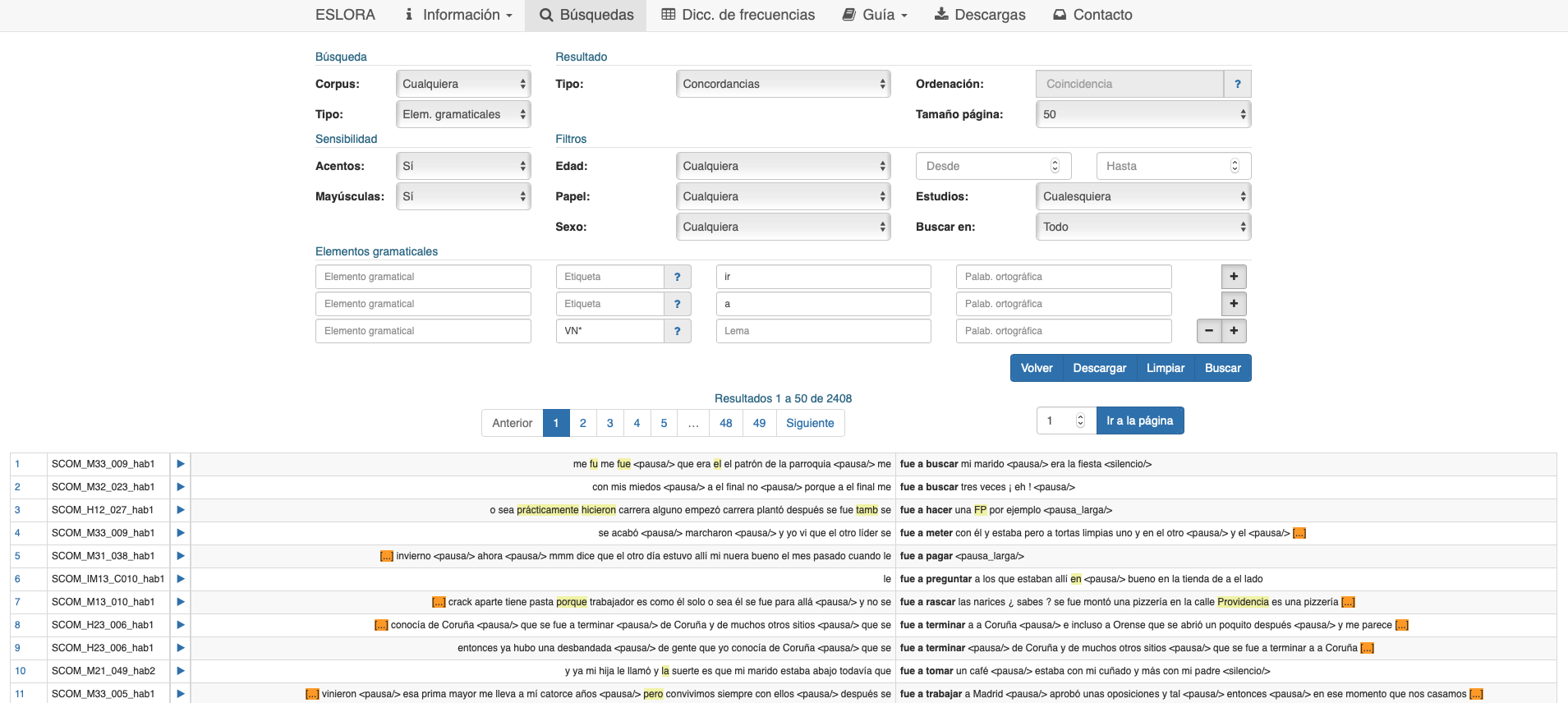
Es posible hacer búsquedas de secuencias basadas en rasgos gramaticales netos, totalmente desvinculados de factores léxicos. Por ejemplo, marcar en tres campos de etiqueta sucesivas los rasgos N, A y A nos permite recuperar los casos de un sustantivo seguido de dos adjetivos, del tipo canción tradicional francesa, centro comercial enorme, etc. Si, en esta misma opción, abrimos cuatro unidades y vamos marcando en la etiqueta de la primera, en el lema de la segunda, nombre en la etiqueta de la tercera y adjetivo en la etiqueta de la cuarta, obtendremos todos los casos del tipo años de dedicación exclusiva, conductos de aire caliente y similares, que dan una buena muestra de la potencia de la aplicación.
Otra posibilidad integrada en el sistema de búsqueda del corpus consiste en la recuperación de casos en los que una forma ortográfica coaparece con otra en una ventana contextual que, en la versión actual, puede tener una extensión de hasta diez palabras. Así, por ejemplo, podemos recuperar los ejemplos en los que la forma ortográfica casa lleva a su derecha la forma ortográfica abuelos a una distancia igual o inferior a cinco palabras. La forma de hacerlo consiste en activar la opción Palabras ortográficas próximas en el tipo de búsqueda, escribir luego casa en el campo correspondiente a la primera forma y abuelos en el segundo. En la versión actual, la búsqueda es sensible al orden de los elementos, de modo que con la organización mencionada obtendremos casos del estilo de la casa de mis abuelos, la casa de unos abuelos y también en mi casa siempre vivimos todos juntos, abuelos incluidos. La ordenación contraria recuperará casos del tipo mis abuelos estaban viviendo en la casa de mis tíos, etc.
Una generalidad considerablemente mayor se consigue, como es lógico, con la opción Elementos gramaticales próximos. Con un ejemplo sencillo, la combinación de acordarse con la preposición de puede aparecer en casos en los que los dos elementos no están situados inmediatamente. Utilizar esta opción de búsqueda y escribir el lema acordar en el primer campo y el lema de en el segundo devuelve casos como me acuerdo mucho de..., me acuerdo muy bien de..., no me acordaba yo de esta grabadora, etc. Más interesante todavía es la utilización de esta opción para paliar algunos de los inconvenientes que ocasiona el análisis en elementos gramaticales, inevitable si se quiere poder recuperar la información abstracta que requiere la investigación de los fenómenos gramaticales. Así, la búsqueda ejemplificada en la figura 6 para obtener los casos de la perífrasis ir a + infinitivo recupera ejemplos como voy a decir, vamos a hacer, pero no los del tipo irse a bañar, vete a buscar, etc. La razón es evidente: las formas gráficas irse y vete contienen dos elementos gramaticales y, por tanto, no responden a la secuencia verbo ir seguido de preposición a y seguido de verbo en infinitivo. La forma de recuperar casos de este tipo es, precisamente, la búsqueda por proximidad. Dado que solo admite dos elementos, la estrategia más adecuada consiste en escribir el lema ir en el primer campo y un verbo en infinitivo en el segundo, con una ventana de, por ejemplo, cinco elementos. Con ello se obtendrán todos los casos en los que el infinitivo sigue inmediatamente a la preposición, pero también aquellos en los que hay otros elementos intermedios (con lo que no todos los casos serán relevantes para el trabajo con la perífrasis).
Notas
- No, naturalmente, de todos los elementos gramaticales que la componen, sino de aquellos implicados en la distinción establecida habitualmente entre “palabra gráfica” y “palabra gramatical”. Así, las palabras gráficas al o decirte contienen dos palabras o elementos gramaticales cada una de ellas, vinculados a los lemas a y el en el primer caso y decir y te en el segundo. Cf. infra para las implicaciones de este tratamiento en el sistema de búsqueda. ↩
- La frecuencia normalizada permite obtener una visión general del mayor o menor peso estadístico del elemento recuperado con independencia del volumen del conjunto textual con el que se trabaje (que es lo que proporciona la frecuencia general). Dado que la frecuencia de los elementos lingüísticos es relativamente baja, expresarla en forma de porcentajes no es de gran ayuda, por lo que se presenta habitualmente no en la forma de casos por cien, sino de casos por cien mil palabras o por millón de palabras. ↩